Reference:b站翼云图灵, 黑书, 坂井
第一章
主要就是讲计算机性能的一些计算公式,熟练理解就好 补充一个大端方式(Big-Endian)和小端方式(Little-Endian)的区别 例如16bit宽的数0x1234(12是高位,34是低位)
小端模式是指数据的低位保存在内存的低地址中,而数据的高位保存在内存的高地址中。
内存地址
0x4000
0x4001
存放内容
0x34
0x12大端模式是指数据的低位保存在内存的高地址中,而数据的高位保存在内存的低地址中.
内存地址
0x4000
0x4001
存放内容
0x12
0x34
第二章
这一章主要讲解MIPS汇编指令,还有三种寄存器寻址,课件里面讲的很全面了。补充练习黑书和坂井的课后习题。
1. MIPS的通用寄存器是32位长,约定1字 = 32b = 4B, 所以在算偏移地址的时候会有个index 左移2位(sll, $Reg1, $Reg2, 2), 因为计算机内存是按字节(Byte)编址。
2. 装载32位立即数过程是:先取高位(lui);然后再与低位立即数(ori),至于为什么不能用addi?因为低16位如果全是是1,addi会把它理解为负数
3. 一般汇编语言步骤是:取基地址 --> 计算移位量 --> 运算 --> 写回(⚠️写回的汇编语言方向是从左到右!!!!)
4. 注意三种指令格式的机器码(会有交叉)
5. PC寄存器是+4+相对地址
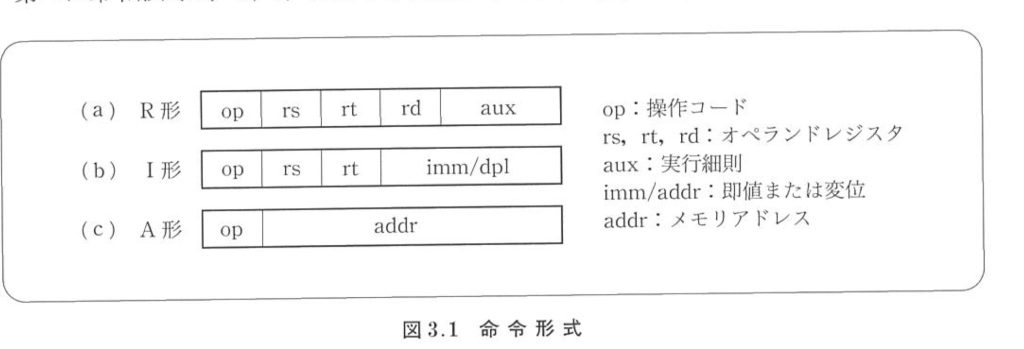
⬆️坂井书里面把J型命令叫做A形,里面逻辑左移是sla,逻辑右移是sra;黑书里面则是sll(Shift Left Logical), srl(Shift Right Logical)
书里面关于三种寻地方式有一个很直观的图

第三章
这一章主要讲算数运算和一些运算电路的逻辑结构
0正1负,原码(True Form)由1位符号位和剩下的数值位表示,有两种0的表示(+0和-0)
反码(1's complement):正数的反码和原码相同;负数是符号位为1,其它位是原码取反。
补码(2's complement): 正数的补码和原码,反码相同;负数是符号位为1,其它位是原码取反,未位加1。
行波进位加法器(Ripple Carry Adder):串联起来,不断进位
超前进位加法器(Carry-lookahead Adder ): 四个加法器件为一组,抽象为1个组的进位
(具体实现细节参考数电学习章节>>>>这些逻辑器件底层实现蛮重要的‼️涉及到符号位扩展)
浮点数(float point number):IEEE754规定32位,最高位是符号位(sign),随后是8位指数域(exponent),剩下的表示尾数(fraction),计算出真正的指数(阶数)之后还要加上127的偏阶,64位的浮点数则是要加上1023的偏阶
㊙️补充:
8位二进制原码的表示范围:-127~+127。
8位二进制反码的表示范围:-127~+127。
8位二进制补码的表示范围:-128~+127。 -128的补码是1000 0000(因为没有-0的补码表示了,所以负数范围会多一个)
第四章
这章的重点是流水线(pipeline),而且黑书和坂井有很大的出入……
黑书里面把一个指令周期(instruction circle)分为了5个阶段:
1️⃣取指阶段(Instruction Fetch, IF):从内存中取出指令。
2️⃣指令译码阶段(Instruction Decode, ID):对取出的指令进行解码,确定操作类型和操作数。
3️⃣执行阶段(Execute, EX):执行指令的操作,可能涉及算术逻辑运算、数据传输等。
4️⃣访存阶段(Memory Access, MEM):如果指令需要访问内存,则在这个阶段进行读写操作。
5️⃣写回阶段(Write Back, WB):将执行阶段的结果写回到寄存器中。
坂井则是把EX和MEM两个阶段合成了一个阶段,不是每条指令都要用完5个阶段的!!!!
流水线的一些计算:
⏰时钟周期数 = 指令数 + 流水级数 - 1 (画图✍️轻松理解⭕️)
⏩理想加速比 = 流水线级数
5个流水阶段里面取最慢的一个阶段作为时钟⏰周期
流水线的三种冒险:
结构冒险(Structural Hazard):由于硬件资源有限,无法满足所有指令同时需要的情况,导致竞争。eg.两条指令同时抢占同一流水级的硬件部件
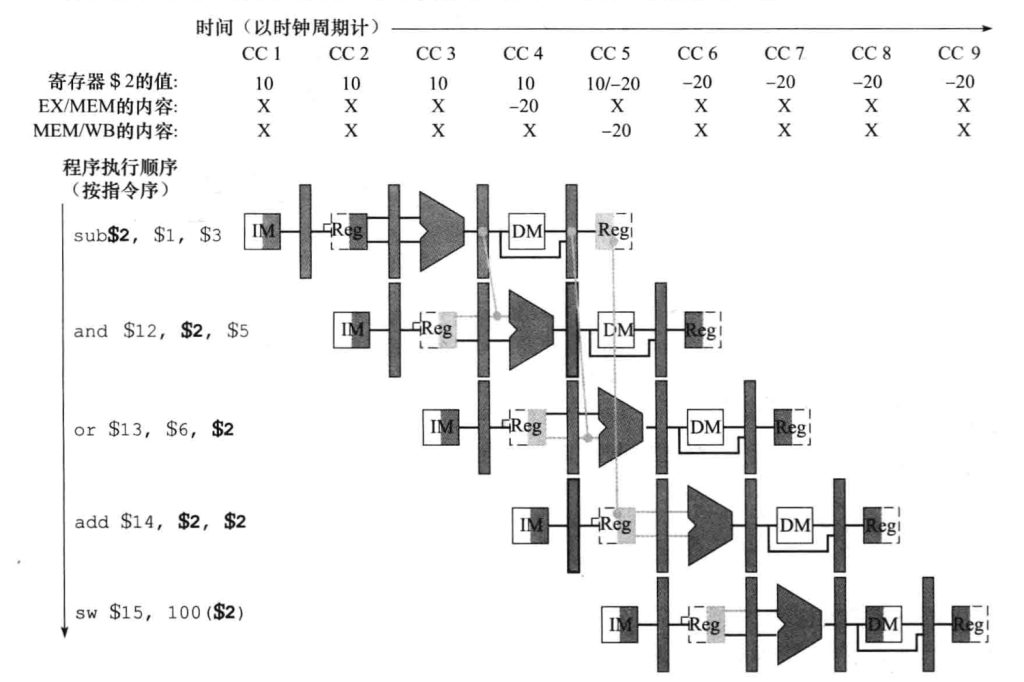
数据冒险(Data Hazard):由于指令之间存在数据依赖关系,后一条指令需要用到前一条指令的结果,但前一条指令的结果尚未准备好,导致数据冒险。eg.寄存器还没写入就要读数据📊
约定寄存器是前半拍读,后半拍写,因此可以用转发(forward)和旁路(bypass)来解决数据冒险
转发的流水线实现看图👀(重点记忆)
控制冒险(Control Hazard):由于分支指令的存在,流水线中的指令在分支条件确定之前无法继续执行,导致控制冒险。
解决办法是加入气泡🫧(nop)阻塞,或者进行分支预测(branch prediction)
数据相关性是指在程序执行过程中,指令之间由于数据的依赖关系(data dependency)而产生的一种关系。数据相关性通常分为三种类型(根据字面意思理解即可):
读后写相关性(RAW,Read After Write):指令A写入的数据在之后被指令B读取。这种相关性表示指令B依赖于指令A的结果,需要等待指令A完成后才能执行。例如,如果指令A将结果存储到内存中,指令B需要从内存中读取这个结果,就会产生读后写相关性。
写后读相关性(WAR,Write After Read):指令A读取的数据在之后被指令B写入。这种相关性表示指令B的写入可能会覆盖指令A读取的数据,导致程序错误。为了避免这种情况,需要调整指令的执行顺序或者使用其他方法解决。
写后写相关性(WAW,Write After Write):指令A和指令B都写入相同的数据位置。这种相关性表示两条指令可能会相互覆盖对方的结果,导致程序错误。同样,需要采取措施避免这种情况发生。
Flow dependency (真依赖/RAW) 在流水线设计中尤为关键,因为它直接影响到指令的执行顺序和CPU的效率。处理这种依赖的策略包括使用流水线暂停(stalling)和前递技术(forwarding)。暂停是指在数据准备好之前,暂时停止后续指令的执行;而前递技术则是尝试提前将计算结果从流水线的一个阶段传递到需要它的后续阶段,从而减少或避免暂停。这些技术都是为了减少由于数据依赖而引起的流水线延迟,提高处理效率。
第五章
这一章主要讲cache和TLB的基本原理,很操作系统,理解量也很大
局部性原理(Principle of Locality):分别为时间局部性和空间局部性。时间局部性(Temporal Locality)指的是如果程序中的某个数据被访问过一次,那么在不久的将来它很可能会再次被访问到。这意味着在短时间内,同一块内存地址被反复访问的可能性很大。
空间局部性(Spatial Locality)指的是如果程序中的某个数据被访问过一次,那么在不久的将来其附近的数据也可能会被访问到。这意味着在短时间内,相邻的内存地址被反复访问的可能性很大。
Cache的相关计算都可以直观理解,命中率🎯
三种映射:
直接映射(Direct Mapping):
直接映射是最简单的映射方式,也是最常见的方式之一。
在直接映射中,主存中的每个数据块只能映射到缓存中的特定位置,这个位置通常是通过对主存地址进行散列计算得到的。
当需要访问一个数据块时,先通过计算得到该数据块在缓存中的位置,然后将其加载到缓存中。
直接映射的优点是实现简单,成本低廉。缺点是容易发生冲突(即不同的数据块映射到了同一个缓存位置),可能会降低缓存的命中率。
全相联映射(Fully Associative Mapping):
在全相联映射中,主存中的任何一个数据块都可以映射到缓存中的任何一个位置,即不需要事先指定映射位置,缓存中的每个位置都可以存储任意的数据块。
当需要访问一个数据块时,需要在缓存中进行搜索,找到对应的位置。
全相联映射的优点是不存在映射冲突,可以充分利用缓存的空间。缺点是实现复杂,成本较高。
实现算法LRU(Least Recently Used)
组相联映射(Set Associative Mapping):
组相联映射是直接映射和全相联映射的一种折中方式。
在组相联映射中,缓存被划分为多个组(Sets),每个组包含多个缓存行(Cache Line)。每个数据块可以映射到某一个组内的任意一个位置。
当需要访问一个数据块时,首先确定它所属的组,然后在这个组内搜索对应的位置。
组相联映射的优点是相对于直接映射,可以减少映射冲突,提高命中率。缺点是相对于全相联映射,实现稍微复杂一些。
Cache组号 = 内存块号 % Cache组数
这里的计算真的很容易迷惑忘记掉....多看例题回顾
Cache块大小(根据图来记忆):(有效位(1位)+ 标记位 + 数据位)* 行数,块大小的计算一定要看一下例题,在没说说明有效位的情况下就不考虑了,直接Cache块大小的 = 块的个数 * 块的大小。Cache的示意图参照下面
缺失分类3C模型:
1️⃣冷启动强制缺失(compulsory miss |cold miss):
冷缺失指的是在缓存刚被创建或清空后,由于缓存中没有任何数据,导致第一次访问缓存时未命中的情况。
冷缺失通常发生在程序刚开始执行、或者在重启后的初始阶段,此时缓存中没有任何有用的数据,所以无法命中。
2️⃣容量缺失(capacity miss):
容量缺失指的是由于缓存空间不足,导致缓存中存储的数据被淘汰,从而导致后续访问这些数据时未命中的情况。
容量缺失通常发生在缓存的容量有限,无法同时存储所有需要的数据时。当缓存已经存满数据,而又有新的数据需要被缓存时,之前缓存的一部分数据会被淘汰,这就可能导致容量缺失。
3️⃣冲突碰撞缺失(conflict miss):
冲突缺失指的是由于缓存映射方式的限制,导致多个数据块被映射到同一个缓存位置,从而导致后续访问这些数据时未命中的情况。
冲突缺失通常发生在直接映射或组相联映射中,由于特定的映射规则,不同的数据块可能会被映射到相同的缓存位置,这就可能导致冲突缺失。
缺失处理的策略:
1️⃣写直达(write through):
写直达是指每次对缓存的写操作都会同时更新主存中的对应数据,即缓存和主存中的数据保持一致。
写直达的优点是简单直接,保证了数据的一致性,但缺点是频繁的主存写操作可能会降低性能,尤其是当写操作频繁时。
2️⃣写回(write back):
写回是指在对缓存的写操作只会更新缓存中的数据,不会立即更新主存,而是在缓存中的数据被替换时,才将修改后的数据写回主存。
写回的优点是减少了对主存的写操作次数,提高了性能,但缺点是可能会导致缓存和主存中的数据不一致,需要额外的管理策略来保证数据一致性。
TLB快表(Translation-Lookaside Buffer):TLB用于加速虚拟地址到物理地址的翻译,CPU访存时需要先拿虚拟地址读取页表(Page Table)得到物理地址,TLB保存了部份虚拟页号的映射信息,所以TLB是页表的Cache,内存是磁盘的Cache。
TLB的组成为:1个有效位 + 1个脏位 + 1个重写位 + 物理页磁盘地址
内存和磁盘的页大小要相同,物理页号+页内偏移 拼接形成物理地址
虚拟地址的完整访存过程一定要看图记忆!!!!
简单来说:TLB是加快虚拟地址到物理地址的转换,在CPU拿到物理地址的时候再进行读取的时候,就要找Cache里面是否有数据
Cache的数据获取策略📊:
1️⃣Demand Fetch(需求获取):
需求获取是一种被动的数据获取策略。当CPU需要某个数据时,它会检查该数据是否已经在缓存中。如果数据不在缓存中(即发生了缓存未命中,或者称为cache miss),那么系统会从主存中获取这个数据。
这种策略的优点是简单,只有在需要数据时才会获取,避免了不必要的数据获取。但是,如果数据不在缓存中,那么CPU需要等待数据从主存中获取,这会导致延迟。
2️⃣Prefetch(预取):
预取是一种主动的数据获取策略。系统会预测CPU接下来可能需要的数据,并提前从主存中获取这些数据,将它们存放到缓存中。
这种策略的优点是可以减少CPU等待数据的时间,从而提高执行效率。但是,预取需要预测算法来预测接下来可能需要的数据,如果预测不准确,可能会浪费带宽和缓存空间。
预取可以通过软件(如编译器或程序员插入的预取指令)或硬件(如CPU内部的预取机制)来实现。
仔细看:关于CPU访存的一篇文章
暂时完结🎉剩下的通过刷过去问查漏补缺
