reference: 黑书,https://zhuanlan.zhihu.com/p/536470404
其实感觉没太大复习的必要了……不过主要的算法思想还是记忆一下,多刷leetcode保持手感吧!
第一部份:基础
这一部份主要复习算法性能分析和10大排序
时间复杂度(Time Complexity):列出递推式,然后用主定理(Master theorem)解决,注意第二种情况的时候要多✖️logn。当然还有一写常见的递推式可以直接看出来时间复杂度。注意三个符号表示上界,下界,紧确界。单调性(monotonicity),单调递增(monotonically increasing)。
插入排序(Insertion Sort):最优O(N),最坏O(N^2),类比打牌边摸牌边整理牌。
归并排序(Merge Sort):类比左右手摸切好的牌然后比较。
快速排序(Quick Sort):选好一个pivot然后根据pivot分成两部份再递归下去
堆排序(Heap Sort):建堆,取头节点,不断维护堆的排序过程
桶排序(Bucket Sort):一个桶放一定范围的元素,空间换时间
冒泡排序(Bubble Sort):不断把最大的元素沉底
选择排序(Selection Sort):不断迭代选最小的元素
希尔排序(Shell Sort):定一个gap数值,然后gap不断二分下来
基数排序(Radix Sort):从最低位依次开始比较(个位->十位->百位->.....)
计数排序(Counting Sort):最经典的用空间换时间
Insertion Sort
#include<bits/stdc++.h>
using namespace std;
void insertionSort(int arr[], int n){
int i , j , key;
for(int i = 1; i < n; i++){
key = arr[i];
j = i - 1; // j指向已排好序的子数组的最后一个元素
while(j >= 0 && arr[j] > key){ // 不断找key放下的位置
arr[j + 1] = arr[j];
j = j - 1;
}
arr[j + 1] = key; // 放下key
}
}
void printArray(int arr[], int n){
for(int i = 0; i < n; i++) cout << arr[i] << " ";
cout << endl;
}
int main() {
int arr[] = {12, 11, 13, 5, 6};
int n = sizeof(arr) / sizeof(arr[0]);
insertionSort(arr, n);
printArray(arr, n);
return 0;
}
//5 6 11 12 13
//最好情况:当输入数组已经是排序好的情况,插入排序只需要进行 n−1次比较,没有元素交换的操作。所以最好情况下的时间复杂度为 O(n)
//最坏情况:当输入数组是逆序的情况,每次插入都需要比较和移动所有的已排序元素。所以最坏情况下的时间复杂度为 O(n2)Merge Sort
#include<bits/stdc++.h>
using namespace std;
void merge(int arr[], int l, int m, int r){
int i, j , k;
int n1 = m - l + 1;
int n2 = r - m;
int L[n1], R[n2]; // 创建两个临时数组
// 复制数据到临时数组
for(int i = 0; i < n1; i++) L[i] = arr[l + i];
for(int j = 0; j < n2; j++) R[j] = arr[m + 1 + j];
// 合并临时数组回原数组
i = 0;
j = 0;
k = l;
while(i < n1 && j < n2){
if(L[i] < R[j]) arr[k++] = L[i++];
else arr[k++] = R[j++];
}
while(i < n1) arr[k++] = L[i++]; // 复制剩余的L[],如果有的话
while(j < n2) arr[k++] = R[j++]; // 复制剩余的R[],如果有的话
}
void mergeSort(int arr[], int l, int r){
if(l < r) {
int m = l + (r - l) / 2; // 找到中间索引
mergeSort(arr, l, m); // 分治两个子数组
mergeSort(arr, m + 1, r);
merge(arr, l, m, r); // 归并
}
}
// 打印数组元素
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++)
cout << arr[i] << " ";
cout << endl;
}
int main() {
int arr[] = {12, 11, 13, 5, 6};
int arr_size = sizeof(arr) / sizeof(arr[0]);
mergeSort(arr, 0, arr_size - 1);
cout << "排序后的数组:\n";
printArray(arr, arr_size);
return 0;
}
//排序后的数组:
//5 6 11 12 13
//归并排序的时间复杂度是比较稳定的,无论是最好情况、最坏情况,还是平均情况,时间复杂度都是(nlogn)Quick Sort
#include<bits/stdc++.h>
using namespace std;
int partition(vector<int>& arr, int low, int high){
int pivot = arr[high];
int i = low - 1;
for(int j = low; j < high; j++){
if(arr[j] < pivot){
i++;
swap(arr[i], arr[j]);
}
}
swap(arr[i + 1], arr[high]);
return i + 1;
}
void quickSort(vector<int>& arr, int low, int high){
if(low < high){
int pi = partition(arr, low, high);
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
int main(){
vector<int> arr = {38, 23, 10, 6, -100, 40};
int n = (int)arr.size();
quickSort(arr, 0, n - 1);
for(auto x : arr) cout << x << " ";
return 0;
}
//-100 6 10 23 38 40
//时间复杂度根据递归树深度,最深的时候就是已排好的数组,最好的时候每次都对半划分
//最坏O(n^2), 最优O(nlogn)Heap Sort
#include<bits/stdc++.h>
using namespace std;
// 建的最大堆
void heapify(vector<int>& arr, int n, int i){
int largest = i;
int left = 2 * i + 1;
int right = 2 * i + 2;
if(left < n && arr[left] > arr[largest]) largest = left;
if(right < n && arr[right] > arr[largest]) largest = right;
if(largest != i){
swap(arr[largest], arr[i]);
heapify(arr, n, largest); //递归下去,调整堆
}
}
void heapsort(vector<int>& arr){
int n = (int)arr.size();
for(int i = n / 2 - 1; i >= 0; i--)
heapify(arr, n, i); // 从非叶子节点开始建堆
for(int i = n - 1; i >= 0; i--){
swap(arr[i], arr[0]); // 交换头节点
heapify(arr, i, 0); // 继续建堆,有在减小规模
}
}
int main(){
vector<int> arr = {-41, 27, 89, 0, 2, 7, 10};
heapsort(arr);
for(auto x : arr) cout << x << " ";
return 0;
}
//-41 0 2 7 10 27 89
// 建堆O(N), 每次删除元素调整堆O(logN)
// 时间复杂度是稳定的O(NlogN)Bubble Sort
#include<bits/stdc++.h>
using namespace std;
void bubbleSort(vector<int>& arr){
int n = (int)arr.size();
for(int i = 0; i < n - 1; i++){
for(int j = 0; j < n - i - 1; j++){
if(arr[j] > arr[j + 1]) swap(arr[j], arr[j + 1]);
}
}
}
int main(){
vector<int> arr = {64, 34, 25, 12, 22, 11, 90};
bubbleSort(arr);
for(auto x : arr) cout << x << " ";
return 0;
}
//11 12 22 25 34 64 90
//最好情况O(N):当输入数组已经是排序好的(即完全升序或降序),冒泡排序只需要进行一次遍历就可以确认排序已完成。
//最坏情况O(N^2):当输入数组是完全反序的(即完全降序或升序)
Selection Sort
#include<bits/stdc++.h>
using namespace std;
void selectionSort(vector<int>& arr){
int n = (int)arr.size();
for(int i = 0; i < n - 1; i++){
int min_idx = i; //找到最小元素的索引
for(int j = i + 1; j < n; j++){
// 更新最小元素索引
if(arr[j] < arr[min_idx]) min_idx = j;
}
swap(arr[min_idx], arr[i]);
}
}
int main(){
vector<int> arr = {64, 34, 25, 12, 22, 11, 90};
selectionSort(arr);
for(auto x : arr) cout << x << " ";
return 0;
}
//11 12 22 25 34 64 90
// 稳定的O(N^2)
Bucket Sort
#include<bits/stdc++.h>
using namespace std;
// 获取x的第d位数字
int getDigit(int x, int d){
int t[] = {1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000};
return (x / t[d]) % 10;
}
void radixSort(vector<int>& arr){
int n = (int)arr.size();
int max_num = *max_element(arr.begin(), arr.end());
int d = 0; // 最大的位数
while(max_num){
max_num /= 10;
d++;
}
vector<vector<int>> bucket(10);
for(int i = 0; i < d; i++){
for(int j = 0; j < n; j++){
bucket[getDigit(arr[j], i)].push_back(arr[j]);
}
int idx = 0;
for(int j = 0; j < 10; j++){
for(int k = 0; k < bucket[j].size(); k++)
arr[idx++] = bucket[j][k];
bucket[j].clear();
}
}
}
int main(){
vector<int> arr = {170, 45, 75, 90, 802, 24, 2, 66};
radixSort(arr);
for(auto x : arr) cout << x << " ";
return 0;
}
Counting Sort
#include<bits/stdc++.h>
using namespace std;
void countingSort(vector<int>& arr){
int max_val = *max_element(arr.begin(), arr.end());
vector<int> count(max_val + 1, 0);
for(auto num : arr) count[num]++; //统计每个元素出现次数
int idx = 0;
for(int num = 0; num <= max_val; num++){
while(count[num]-- > 0){
arr[idx++] = num;
}
}
}
int main(){
vector<int> arr = {1, 4, 1, 2, 7, 5, 2};
countingSort(arr);
for(auto x : arr) cout << x << " ";
return 0;
}第二部分:图算法
并查集(Union-Find)是一种处理不交集合合并及查询问题的数据结构,特别适用于那些不断合并集合而又需要快速判断元素间是否相连的场景。在并查集中,每个元素指向一个父节点,一组相连的元素会共同指向一个共同的根节点。并查集主要支持两种操作:find(查找元素的根节点)和 union(合并两个元素所在的集合)。注意初始化的时候,每个元素的父节点指向自己,然后考虑按秩序合并(Union by Rank)和路径压缩(Path Compression)的两种优化
#include<bits/stdc++.h>
using namespace std;
class UnionFind{
private:
vector<int> parent;
vector<int> rank; // 用于按秩合并优化,根节点的rank表示树的高度,用于合并判断
public:
UnionFind(int n){
parent.resize(n);
rank.resize(n);
for(int i = 0; i < n; i++) parent[i] = i; //初始时,每个元素的父节点指向自己
}
int find(int x){
// if(parent[x] != x){
// parent[x] = find(parent[x]); //最关键的一步,路经压缩优化
// }
// return parent[x];
return parent[x] == x ? x : find(parent[x]);
}
void unionSets(int x, int y){ // 按秩合并(Union by Rank)
int rootX = find(x);
int rootY = find(y);
//如果两个根节点的 rank 不同,将 rank 较小的根节点的父节点设置为 rank 较大的根节点。这样做不会增加树的高度。
if(rootX != rootY){
if(rank[rootX] > rank[rootY]){
parent[rootY] = rootX;
}
else if(rank[rootX] < rank[rootY]){
parent[rootX] = rootY;
}
else{
parent[rootY] = rootX;
rank[rootX] += 1;
}
}
}
bool connected(int x, int y){
return find(x) == find(y);
}
int getRank(int x){ // 返回已经路径压缩后的节点的rank
return rank[find(x)];
}
};
int main(){
UnionFind uf(10); // // 创建一个包含10个元素的并查集
uf.unionSets(1, 2);
uf.unionSets(2, 3);
uf.unionSets(4, 5);
uf.unionSets(5, 6);
cout << "节点2的父节点是: " << uf.find(2) << endl;
cout << "节点3的父节点是: " << uf.find(3) << endl;
cout << "节点5的父节点是: " << uf.find(5) << endl;
cout << "is 3 and 5 connected? " << uf.connected(3, 5) << endl;
cout << "is 1 and 3 connected? " << uf.connected(1, 3) << endl;
uf.unionSets(1, 4); // 合并两个集合
cout << "节点4的父节点是: " << uf.find(4) << endl;
cout << "is 1 and 4 connected? " << uf.connected(1, 4) << endl;
cout << "合并之后节点5的父节点是: " << uf.find(5) << endl;
cout << "合并之后节点6的父节点是: " << uf.find(6) << endl;
cout << "节点1的秩是: " << uf.getRank(1)<< endl;
return 0;
}
//节点2的父节点是: 1
//节点3的父节点是: 1
//节点5的父节点是: 4
//is 3 and 5 connected? 0
//is 1 and 3 connected? 1
//节点4的父节点是: 1
//is 1 and 4 connected? 1
//合并之后节点5的父节点是: 1
//合并之后节点6的父节点是: 1
//节点1的秩是: 2
Dijkstra 算法是用于解决单源最短路径问题的经典算法,其目标是找到从指定起点到图中所有其他顶点的最短路径。算法使用了一种贪心策略,逐步扩展当前已知最短路径集合,直到覆盖所有顶点。
算法步骤如下:
初始化:将起点的最短路径长度设置为 0,将所有其他顶点的最短路径长度设置为无穷大。
创建一个优先队列(通常使用最小堆实现),用于按照顶点到起点的距离排序,起始时将起点加入队列。
从队列中取出距离起点最近的顶点,并将其标记为已访问。
遍历该顶点的所有邻居,如果通过当前顶点到达邻居的路径比当前已知的最短路径更短,则更新邻居的最短路径,并将邻居加入队列中。
重复步骤 3 和步骤 4,直到队列为空。
通过这种方式,Dijkstra 算法逐步扩展当前已知最短路径集合,确保每个顶点的最短路径被正确计算。最终,对于每个顶点,我们都可以得到从起点到该顶点的最短路径长度。
通俗来说就是一个不断贪心选点的一个过程,复杂度是nlog级别的(优先队列)
具体来说,如果图中存在负权边或者负权环,Dijkstra 算法可能无法给出正确的结果。这是因为算法的贪心性质要求在每一步选择最短路径,如果存在负权边或者负权环,可能会导致算法错误地认为某些路径是最短的,从而产生错误的结果。
因此,Dijkstra 算法通常适用于没有负权边的图,或者说是适用于权重非负的图。对于存在负权边或者负权环的图,通常会使用 Bellman-Ford 算法来解决最短路径问题,因为 Bellman-Ford 算法能够处理负权边,并且能够检测到负权环路。
#include<bits/stdc++.h>
using namespace std;
#define INF INT_MAX
typedef pair<int, int> pii;
typedef vector<vector<pii>> Graph;
vector<int> dijkstra(const Graph graph, int start){
int n = (int)graph.size();
vector<int> dist(n, INF); // 初始化起点到每个点的距离都是∞
dist[start] = 0; // 起点到自身的距离为0
priority_queue<pii, vector<pii>, greater<pii>> pq; // 距离较小的作为优先级别
pq.push({0, start});
while(!pq.empty()){
int u = pq.top().second;
int d = pq.top().first;
pq.pop();
if(d > dist[u]) continue; // 如果当前顶点已经处理过,跳过
for(const auto& edge : graph[u]){ // 遍历当前顶点的邻居
int v = edge.first;
int w = edge.second;
if(dist[u] + w < dist[v]){ //// 更新到邻居的最短距离
dist[v] = dist[u] + w;
pq.push({dist[v], v});
}
}
}
return dist;
}
int main() {
int n = 6; // 顶点数
Graph graph(n);
// 添加边
graph[0].push_back({1, 5});
graph[0].push_back({2, 3});
graph[1].push_back({3, 6});
graph[1].push_back({2, 2});
graph[2].push_back({4, 4});
graph[2].push_back({5, 2});
graph[2].push_back({3, 7});
graph[3].push_back({4, -1});
graph[4].push_back({5, -2});
vector<int> dist = dijkstra(graph, 0);
// 输出结果
for (int i = 0; i < n; ++i) {
cout << "Distance from 0 to " << i << " is " << dist[i] << endl;
}
return 0;
}
//Distance from 0 to 0 is 0
//Distance from 0 to 1 is 5
//Distance from 0 to 2 is 3
//Distance from 0 to 3 is 10
//Distance from 0 to 4 is 7
//Distance from 0 to 5 is 5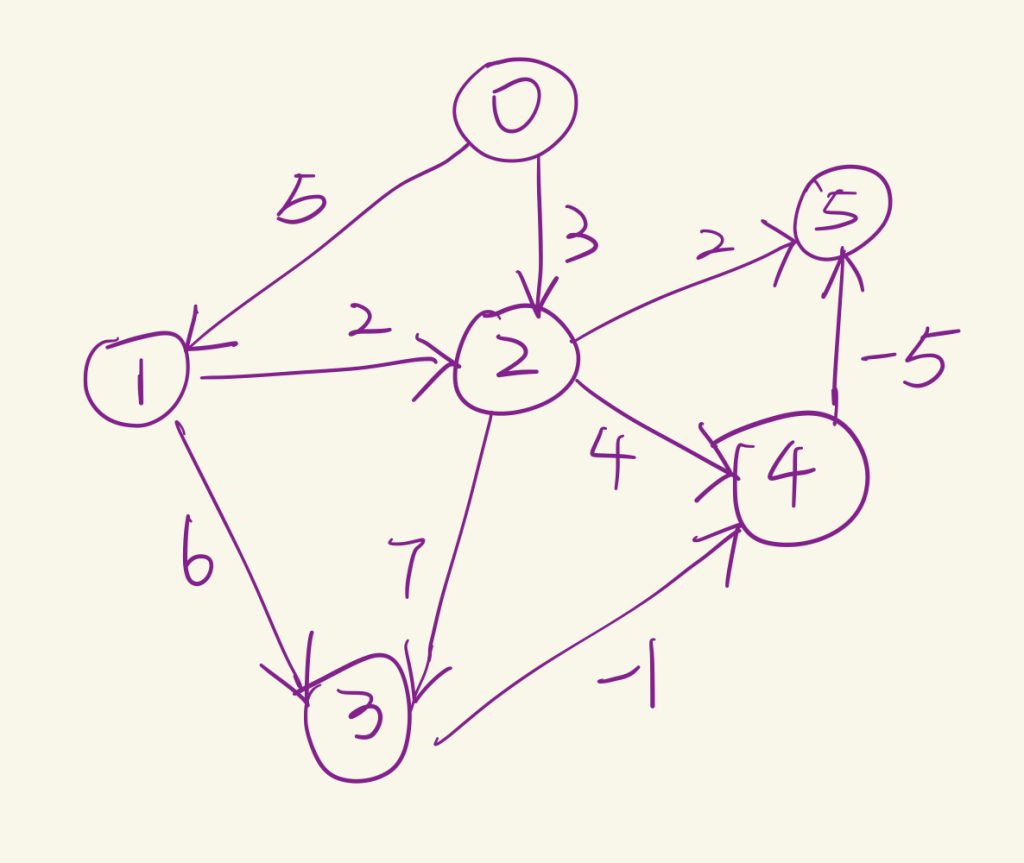
Bellman-Ford算法是一种用于在加权图中找到从单源顶点到所有其他顶点的最短路径的算法。它可以处理负权重的边,但不能处理负权重的环。
原理: Bellman-Ford算法的基本思想是通过反复松弛(relax)所有的边来逐步减小所有顶点的最短路径估计值,直到得到最短路径。"松弛"是指,如果存在一条从顶点u到顶点v的边,且通过这条边可以使得到达v的最短路径长度比当前的估计值更小,那么就更新这个最短路径估计值。
时间复杂度: Bellman-Ford算法的时间复杂度是O(VE),其中V是顶点(Vertex)的数量,E是边(Edge)的数量。这是因为算法需要对所有的边进行V-1次松弛操作。
Bellman-Ford算法适用于以下环境:
1️⃣图中存在负权重的边。
2️⃣需要检测图中是否存在负权重的环。
3️⃣不需要求解所有对最短路径问题,只需要求解单源最短路径问题。
然而,如果图中不存在负权重的边,且需要求解所有对最短路径问题,那么Floyd-Warshall算法或者Dijkstra算法可能会是更好的选择,因为它们的时间复杂度更低。
仔细看代码实现❗️❗️
#include<bits/stdc++.h>
using namespace std;
struct Edge{
int src, dest, weight; //边的起点,终点,权重
};
struct Graph{
int V, E; // 顶点数量,边的数量
struct Edge* edge; // 指向Edge结构体的指针,用于存储图中所有的边
};
struct Graph* createGraph(int V, int E){
struct Graph* graph = new Graph;
graph->V = V;
graph->E = E;
graph->edge = new Edge[E];
return graph;
}
void printArr(int dist[], int n){
cout << "Vertex Distance From Srouce" << endl;
for(int i = 0; i < n; i++) cout << i << " " << dist[i] << endl;
}
void BellmanFord(struct Graph* graph, int src){
int V = graph->V;
int E = graph->E;
int dist[V];
for(int i = 0; i < V; i++) dist[i] = INT_MAX; // 初始化源顶点到其他点的路径长度为∞
dist[src] = 0; // 源顶点到自身距离为0
// 松弛操作(Relaxation):如果从源顶点u经过这条边到达顶点v的距离小于当前存储的从源顶点到顶点v的距离,那么就更新这个距离。
for(int i = 1; i <= V - 1; i++){ // 外层遍历每个点
for(int j = 0; j < E; j++){ // 内存遍历每个边
int u = graph->edge[j].src;
int v = graph->edge[j].dest;
int weight = graph->edge[j].weight;
if(dist[u] != INT_MAX && dist[u] + weight < dist[v])
dist[v] = dist[u] + weight;
}
}
// 检测负权环(Negative Weight Cycle)
//再次遍历每条边,如果还能进行松弛,那么就说明图中存在负权重环。
//因为在V-1次松弛后,如果没有负权重环,那么应该已经找到了最短路径。
//如果还能进行松弛,那么说明存在负权重环,因为每次经过这个环,都可以使得路径更短。
for(int i = 0; i < E; i++){
int u = graph->edge[i].src;
int v = graph->edge[i].dest;
int weight = graph->edge[i].weight;
if(dist[u] != INT_MAX && dist[u] + weight < dist[v]){
cout << "Graph contains negative weight cycle" << endl;
return;
}
}
printArr(dist, V);
return;
}
int main(){
//************ 无负权环的测试******************
int V = 5;
int E = 8;
struct Graph* graph = createGraph(V, E);
// add edge 0-1
graph->edge[0].src = 0;
graph->edge[0].dest = 1;
graph->edge[0].weight = -1;
// add edge 0-2
graph->edge[1].src = 0;
graph->edge[1].dest = 2;
graph->edge[1].weight = 4;
// add edge 1-2
graph->edge[2].src = 1;
graph->edge[2].dest = 2;
graph->edge[2].weight = 3;
// add edge 1-3
graph->edge[3].src = 1;
graph->edge[3].dest = 3;
graph->edge[3].weight = 2;
// add edge 1-4
graph->edge[4].src = 1;
graph->edge[4].dest = 4;
graph->edge[4].weight = 2;
// add edge 3-2
graph->edge[5].src = 3;
graph->edge[5].dest = 2;
graph->edge[5].weight = 5;
// add edge 3-1
graph->edge[6].src = 3;
graph->edge[6].dest = 1;
graph->edge[6].weight = 1;
// add edge 4-3
graph->edge[7].src = 4;
graph->edge[7].dest = 3;
graph->edge[7].weight = -3;
BellmanFord(graph, 0);
//结果:
// Vertex Distance From Srouce
// 0 0
// 1 -1
// 2 2
// 3 -2
// 4 1
//*******************有环的测试情况************************
// int V = 5;
// int E = 6;
// struct Graph* graph = createGraph(V, E);
// // add edge 1-0
// graph->edge[0].src = 1;
// graph->edge[0].dest = 0;
// graph->edge[0].weight = 4;
//
// // add edge 0-4
// graph->edge[1].src = 0;
// graph->edge[1].dest = 4;
// graph->edge[1].weight = 5;
//
// // add edge 3-4
// graph->edge[2].src = 3;
// graph->edge[2].dest = 4;
// graph->edge[2].weight = -2;
//
// // add edge 3-1
// graph->edge[3].src = 3;
// graph->edge[3].dest = 1;
// graph->edge[3].weight = -5;
//
// // add edge 1-2
// graph->edge[4].src = 1;
// graph->edge[4].dest = 2;
// graph->edge[4].weight = 1;
//
// // add edge 2-3
// graph->edge[5].src = 2;
// graph->edge[5].dest = 3;
// graph->edge[5].weight = 2;
// BellmanFord(graph, 1); // 这里要注意传入的起始点是在环上的点时候才会检测出来!
// return 0;
}
////结果:Graph contains negative weight cycle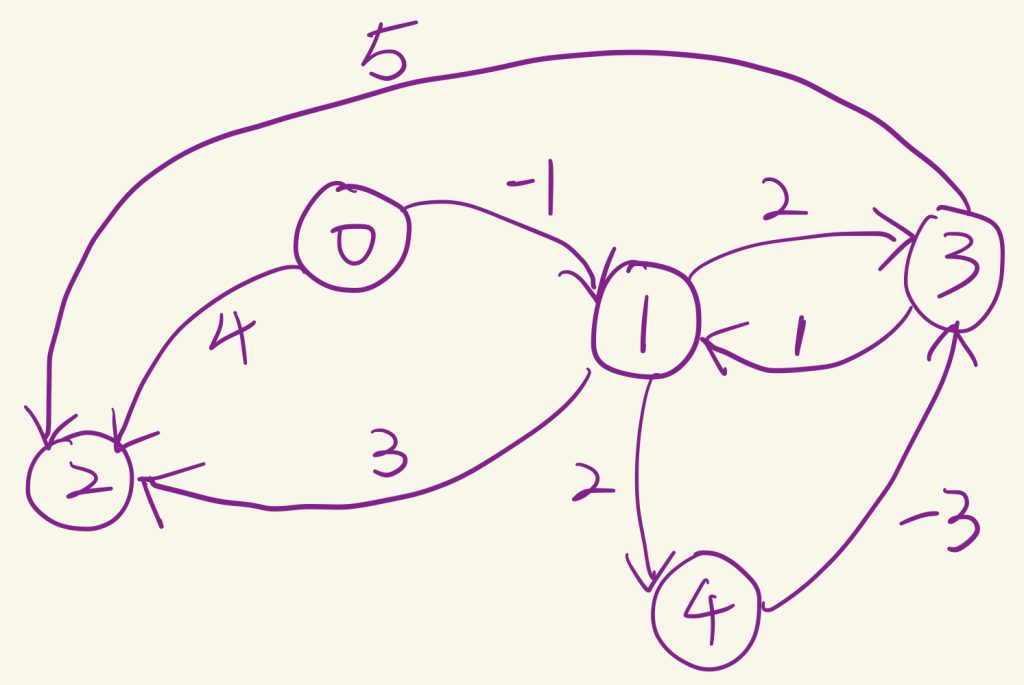
最小生成树算法:Kruskal & Prim
Kruskal算法是一种用于找到连通图的最小生成树的贪心算法。以下是Kruskal算法的基本思想:
初始化:开始时,每个顶点都是一个单独的集合,即每个顶点都是一棵只有一个顶点的树。
排序:将图中的所有边按照权重从小到大排序。(因此时间复杂度是nlogn级别的)
构造最小生成树:遍历排序后的边,对于每一条边,检查它连接的两个顶点是否属于同一棵树(即是否在同一个集合中)。如果不在同一棵树,就将这条边添加到最小生成树中,并将两个顶点所在的树合并为一棵树。如果在同一棵树,就忽略这条边,以防止形成环。
结束:当所有的顶点都在同一棵树(即同一个集合)中时,算法结束。此时,选取的边就构成了图的最小生成树。
Kruskal算法的关键在于它贪心地选择权重最小的边,同时避免形成环。
简要来讲:就是不断地选边
#include<bits/stdc++.h>
using namespace std;
// 定义边的结构体,包含两个顶点 u 和 v,以及这条边的权重 weight
struct Edge {
int u, v, weight;
// 重载 < 运算符,用于比较两条边的权重
bool operator<(Edge const& other) const { // 注意这里添加了 const 关键字
return weight < other.weight;
}
};
// 定义 parent 和 my_rank 向量,用于实现并查集
vector<int> parent, my_rank;
// 并查集的查找操作,用于查找顶点 v 所在的集合
int find_set(int v) {
if (v == parent[v])
return v;
return parent[v] = find_set(parent[v]);
}
// 并查集的创建集合操作,用于创建一个只包含顶点 v 的集合
void make_set(int v) {
parent[v] = v;
my_rank[v] = 0;
}
// 并查集的合并操作,用于将顶点 a 和顶点 b 所在的集合合并为一个集合
void union_sets(int a, int b) {
a = find_set(a);
b = find_set(b);
if (a != b) {
if (my_rank[a] < my_rank[b])
swap(a, b);
parent[b] = a;
if (my_rank[a] == my_rank[b])
my_rank[a]++;
}
}
int main() {
int n = 4; // 顶点的数量
vector<Edge> edges = { // 边的列表
{0, 1, 1},
{1, 2, 2},
{2, 3, 1},
{0, 2, 3},
{0, 3, 4},
{1, 3, 5}
};
// 对所有的边按照权重进行排序
sort(edges.begin(), edges.end());
// 初始化并查集
parent.resize(n);
my_rank.resize(n);
for (int i = 0; i < n; i++)
make_set(i);
// 存储最小生成树的边
vector<Edge> result;
for (Edge e : edges) {
// 如果一条边的两个顶点不在同一个集合中,就将这条边添加到最小生成树中
if (find_set(e.u) != find_set(e.v)) {
result.push_back(e);
union_sets(e.u, e.v);
}
}
// 输出最小生成树的边
for (Edge e : result) {
cout << e.u << " " << e.v << " " << e.weight << "\n";
}
return 0;
}
//0 1 1
//2 3 1
//1 2 2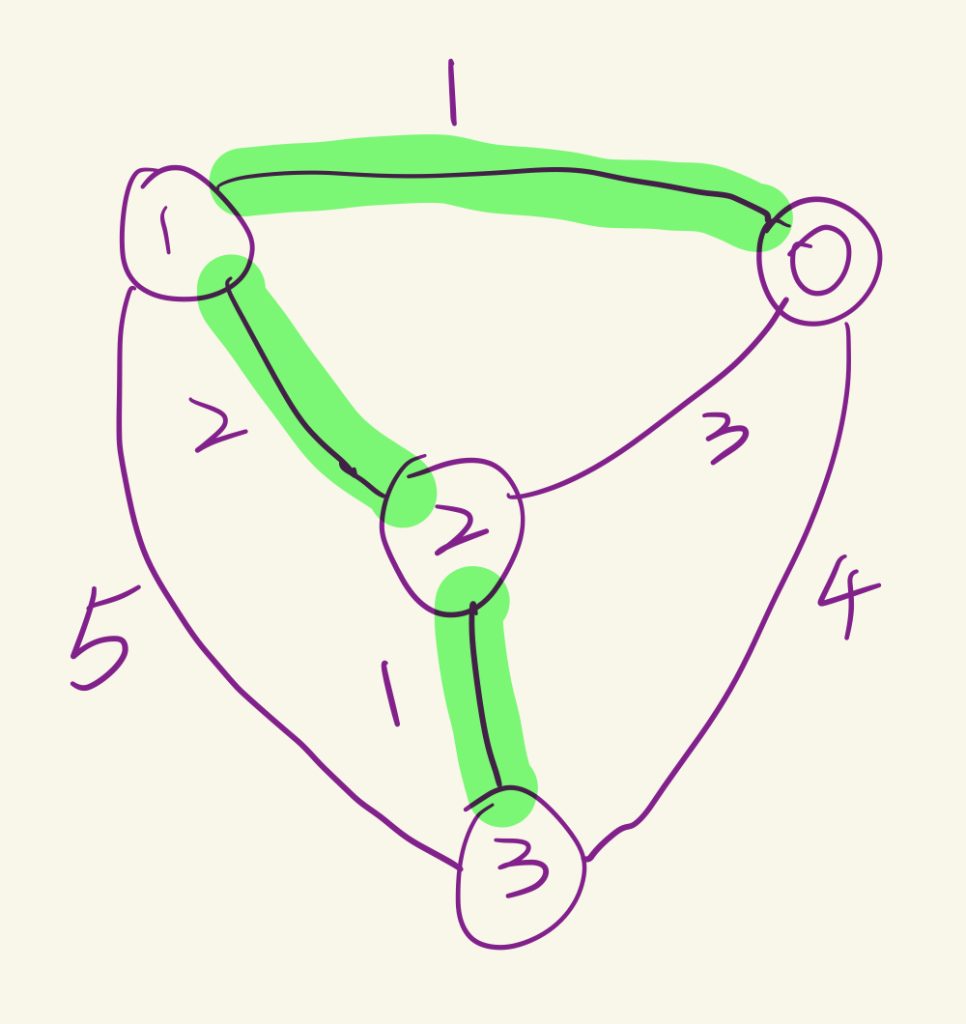
Prim算法(Prim’s Algorithm)是一种用于解决最小生成树问题的贪心算法。以下是该算法的基本步骤:
从图中的任意一个顶点开始,将该顶点加入到最小生成树的集合中。
在剩余的顶点中,找出与已选顶点集合有边相连且权值最小的边,将该边和对应的顶点加入到最小生成树的集合中。
重复第2步,直到所有的顶点都被加入到最小生成树的集合中。
简单来说就是一个不断贪心下去选点的过程。
#include<bits/stdc++.h>
using namespace std;
// 函数minKey用于找到键值最小且未被包含在MST中的顶点
int minKey(vector<int> key, vector<bool> mstSet) {
int min = INT_MAX, min_index = -1;
for (int v = 0; v < key.size(); v++)
if (mstSet[v] == false && key[v] < min) {
min = key[v]; // 更新最小键值
min_index = v; // 更新对应的顶点索引
}
return min_index; // 返回最小键值对应的顶点索引
}
// 函数printMST用于打印生成的最小生成树
void printMST(vector<int> parent, vector<vector<int>> graph) {
cout<<"Edge \tWeight\n";
for (int i = 1; i < parent.size(); i++)
cout<<parent[i]<<" - "<<i<<" \t"<<graph[i][parent[i]]<<" \n";
}
// 函数primMST用于生成最小生成树
void primMST(vector<vector<int>> graph) {
int V = graph.size(); // 获取图中的顶点数量
vector<int> parent(V); // 存储生成的最小生成树
vector<int> key(V, INT_MAX); // 存储键值
vector<bool> mstSet(V, false); // 标记顶点是否已被包含在最小生成树中
key[0] = 0; // 将第一个顶点的键值设为0,使其被选为第一个顶点
parent[0] = -1; // 第一个顶点总是根节点,设其父节点为-1
for (int count = 0; count < V-1; count++) {
int u = minKey(key, mstSet); // 选择键值最小且未被包含在MST中的顶点
mstSet[u] = true; // 将选中的顶点标记为已被包含在MST中
for (int v = 0; v < V; v++)
// 当v未被包含在MST中且u和v之间的权重小于key[v]时,更新父节点和键值
if (graph[u][v] && mstSet[v] == false && graph[u][v] < key[v]) {
parent[v] = u;
key[v] = graph[u][v];
}
}
printMST(parent, graph); // 打印生成的最小生成树
}
int main() {
vector<vector<int>> graph = {{0, 2, 0, 6, 0},
{2, 0, 3, 8, 5},
{0, 3, 0, 0, 7},
{6, 8, 0, 0, 9},
{0, 5, 7, 9, 0}};
primMST(graph); // 生成最小生成树
return 0;
}
//graph[0][1]的值为2,表示顶点0和顶点1之间有一条权重为2的边。
//graph[0][2]的值为0,表示顶点0和顶点2之间没有边。
//graph[3][4]的值为9,表示顶点3和顶点4之间有一条权重为9的边。
//Edge Weight
//0 - 1 2
//1 - 2 3
//0 - 3 6
//1 - 4 5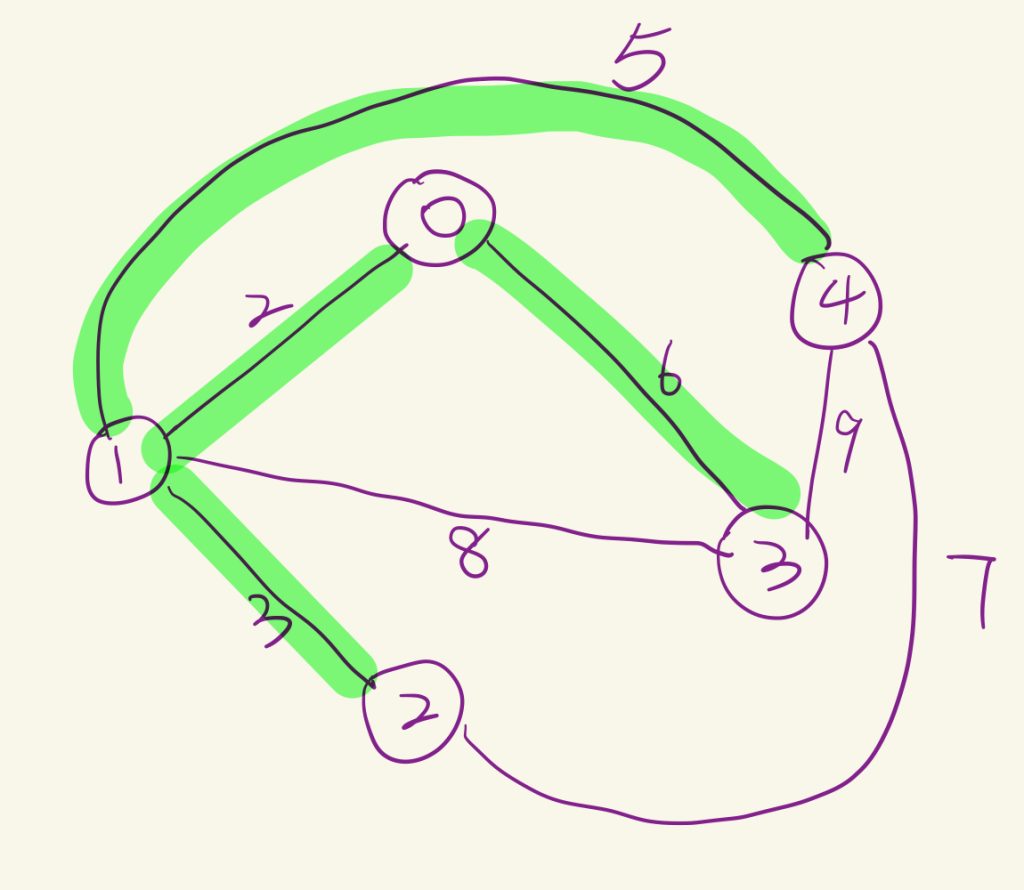
Floyd-Warshall算法(Floyd-Warshall Algorithm)是一种用于解决所有对最短路径问题的关键优化技术。这个有效的算法确定了一个加权图中所有顶点之间的最短距离,无论边的权重是正还是负1。
以下是算法的基本步骤:
初始化解决方案矩阵(Initialize the solution matrix):与输入图矩阵相同作为第一步2。
更新解决方案矩阵(Update the solution matrix):通过考虑所有顶点作为中间顶点(intermediate vertex)。选择所有顶点逐个,并更新包含所选顶点作为中间顶点的最短路径2。
对于源和目标顶点的每一对(i,j),有两种可能的情况2:
k不是从i到j的最短路径中的中间顶点。我们保持dist [i] [j]的值不变。
k是从i到j的最短路径中的中间顶点。我们更新dist [i] [j]的值为dist [i] [k] + dist [k] [j],如果dist [i] [j] > dist [i] [k] + dist [k] [j]。
以下是Floyd-Warshall算法的伪代码:
For k = 0 to n – 1
For i = 0 to n – 1
For j = 0 to n – 1
Distance [i, j] = min (Distance [i, j], Distance [i, k] + Distance [k, j])
在时间复杂度方面,Floyd-Warshall算法的时间复杂度是O(n^3),其中n是图中顶点的数量。这是因为算法需要对每对顶点执行更新操作,这需要三层循环,每层循环都遍历n个顶点。因此,对于大型图,这可能是一个问题,但对于小型图或稠密图,这通常是可以接受的。
#include<bits/stdc++.h>
using namespace std;
#define INF 99999
void floydWarshall(int graph[][4], int V){
int dist[V][V], i, j, k;
// 距离初始化
for(int i = 0; i < V; i++){
for(int j = 0; j < V; j++){
dist[i][j] = graph[i][j];
}
}
for(int k = 0; k < V; k++){ // 用于中转的点
for(int i = 0; i < V; i++){ // 起点
for(int j = 0; j < V; j++){ // 终点
if (dist[i][k] + dist[k][j] < dist[i][j])
dist[i][j] = dist[i][k] + dist[k][j];
}
}
}
// 打印结果
for (i = 0; i < V; i++) {
for (j = 0; j < V; j++) {
if (dist[i][j] == INF)
cout << "INF" << " ";
else
cout << dist[i][j] << " ";
}
cout << endl;
}
}
int main() {
int graph[4][4] = { {0, 1, 2, INF},
{2 , 0, INF, INF},
{INF, INF, 0, 2},
{4, 1, INF, 0} };
floydWarshall(graph, 4);
return 0;
}
//0 1 2 4
//2 0 4 6
//5 3 0 2
//3 1 5 0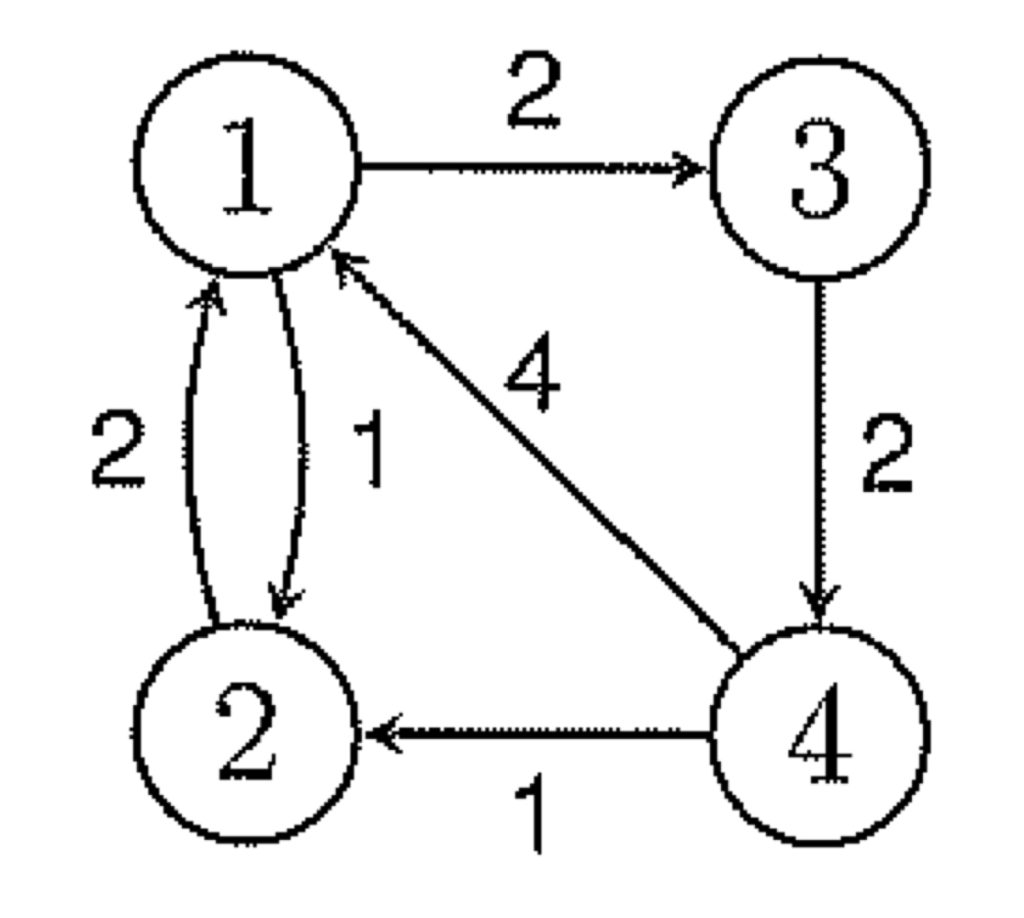
第三部份:动态规划
留个坑